
In applicaties met een lange levensduur kunnen kleine fouten leiden tot grote consequenties. Als een platform niet wordt afgesloten, kan een klein lek over tijd uitgroeien tot een groot probleem. Het ongelimiteerd oplopen van geheugen heet een memory leak. Vaak worden memory leaks in grote bedrijven lange tijd gemanaged met tijdelijke oplossingen, maar eigenlijk wil je dit soort problemen liever niet hoeven managen: je wilt gewoon zorgen dat ze er simpelweg niet zijn.
Bij het opsporen van een memory leak waan je je soms echt een detective. In dit artikel nemen we je graag mee achter de schermen bij Bessy en laten we zien hoe je hiermee om kunt gaan. Om je inzicht te geven in het gehele proces geven we zowel voorbeelden van onze eigen applicatie als gesimuleerde scenario's.
De eerste stap bij het opsporen van een memory leak is het isoleren van het lek tot een Python proces dat draait in onze infrastructuur. We hebben de volgende hypotheses opgesteld:
Het eerste waar je doorgaans naar kijkt bij het debuggen van een memory-probleem is de aanwezigheid van objecten in je codebase waar referenties naar blijven bestaan tussen requests.
Bij bedrijven met legacy is een codebase vaak te groot om helemaal door te lopen. Tools zoals flamegraphs en objgraph (Figuur 1) maken het mogelijk om te achterhalen welke objecten niet afgebroken worden. Dit geeft direct inzicht in welke plek in de codebase je moet kijken.

Hier zie je een voorbeeld van een (gesimuleerde) memory leak, waarbij instances van het ‘Leaky’ object niet worden afgebroken, vanwege circulaire imports.
In parallel maken we outputs van geheugen gealloceerd door PyMem_* en PyObject_*, die voor kleine stukjes geheugen gebruik maken van pymalloc - de Python allocator. De meeste computertalen hebben een ingebouwde allocator die delen van het geheugen van hun eigen proces intern alloceren, zodat ze niet volledig afhankelijk zijn van de default allocator van het OS waarop ze draaien. Dus als je Python code runt, zal pymalloc (de Python allocator) voor kleine objecten (<512 bytes) de memory allocatie zelf beheren.
In ons geval zit de caching in hetzelfde proces als de rest van de applicatie, waardoor er een toename over requests te verwachten is. Echter verwachten we los daarvan constant memory over requests heen.
In Figuur 2 zie je de resultaten van onze eerste tests. De memory en het aantal niet-vrijgegeven objecten nemen toe per request, maar niet als je compenseert voor de caching.

a) toont de totale count van alle objecten getrackt door de garbage collector (blauw), het aantal objecten in de cache (groen) en het verschil tussen die twee (geel).
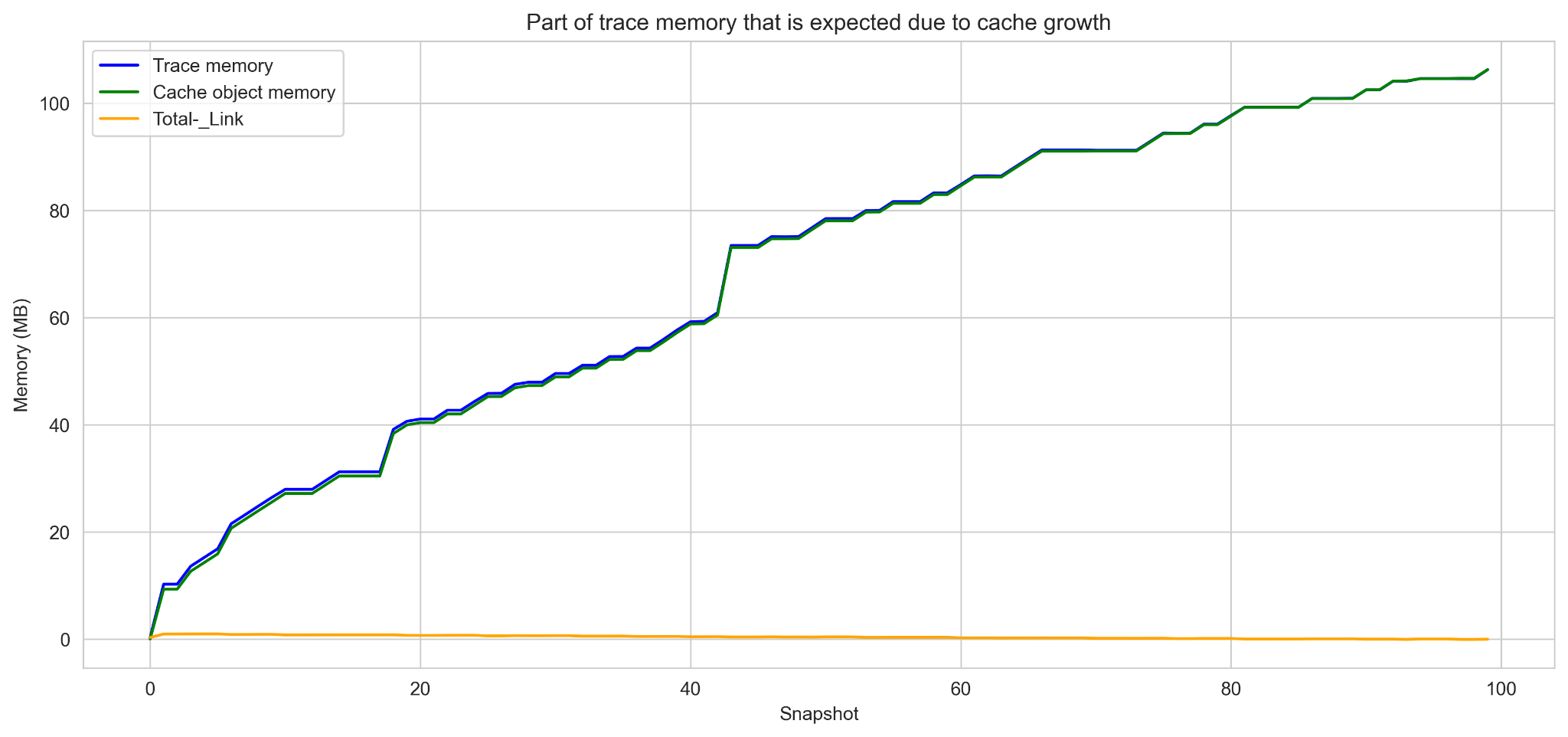
b) toont de total RSS die wordt beheerd met PyMem_* en PyObject_* (blauw), de grootte van de cache (groen) en het verschil tussen die twee (geel). Note: ik heb de garbage collector expliciet aan het begin van iedere request gerund.
De memory neemt dus specifiek toe in het Python proces, maar het is memory dat niet gealloceerd wordt met PyMem_Malloc / PyObject_Malloc. Daarmee kunnen we het eerste groepje mogelijke oorzaken, dat direct terug te zien zou zijn in de reference count van de garbage collector, - zoals circulaire objecten, globale referenties, referenties naar coroutines, etc. - al doorstrepen!
De bevindingen wijzen tot dusver op mogelijke problemen in een van de C/C++ wrappers, of een probleem met de default allocator van het OS die voor dit proces gebruikt wordt.
Memory management van het OS
De kernels van de meest populaire besturingssystemen (linux, macOS, windows) zijn grotendeels geschreven in C. Deze kernels beheren het geheugen. Bij een linux kernel (die vrijwel alle bedrijven in productie gebruiken) kunnen gebruikersprocessen geheugen aanvragen via de system calls ‘brk/sbrk’ en ‘mmap’.
De exacte drempel (brk/sbrk vs. mmap) en de strategie (hoeveel vraag ik op) verschillen per allocator. Standaard shippen de meeste linux distributies met glibc. Glibc’s allocator (die malloc, calloc, realloc en free implementeert) wordt dan ook gebruikt als default allocator voor alles: Cpython, bash, nginx, gunicorn, system daemons, etc. Glibc alloceert het gros van de memory via de heap (alles dat onder het M_MMAP_THRESHOLD zit). Zoals eerder benoemd, zitten er een aantal nadelen aan de heap. In bepaalde scenario’s kan dit leiden tot fragmentatie, waardoor geheugengebruik flink kan toenemen.
Dit leidt ons naar onze tweede hypothese: Wellicht hebben we last van memoryfragmentatie?
De memory van een C/C++ library met een wrapper voor Python wordt beheerd door de allocator ingesteld voor het proces. Wanneer je geen allocator ingesteld hebt, is dit glibc’s malloc. Fragmentatie is bij glibc’s malloc een bekend probleem, omdat het voornamelijk de heap gebruikt. Memory alloceren in de heap is snel - er hoeven niet steeds syscalls naar het OS te worden gedaan voor het opvragen van memory -, maar kent als nadeel dat het met ‘top of heap’ removal werkt. Dit betekent dat chunks midden in de heap niet kunnen worden opgeruimd, ook als ze al wel zijn vrijgegeven en opgenomen in de free list.
Je krijgt veel chunk splitsing op het moment dat je veel objecten van verschillende groottes opslaat. Uiteindelijk blijf je met heel veel “resterende” chunks zitten die te klein zijn om objecten in op te kunnen slaan (welke dus niet teruggegeven kunnen worden, want ze zitten midden in de heap). Dit heet externe fragmentatie.
Default allocators verschillen per OS en kunnen worden overschreven voor specifieke processen. Niet alle populaire applicaties die wij gebruiken, gebruiken dezelfde allocator. Bijvoorbeeld de core backend van Firefox gebruikt de ‘jemalloc’ allocator, en die van Facebook ‘tcmalloc’. Deze allocators, die eigenlijk een herimplementatie van C malloc zijn, maken minder gebruik van de heap en meer gebruik van mmap. Om te voorkomen dat ze steeds syscalls naar het OS maken, vragen ze een grotere hoeveelheid memory aan en hebben ze een eigen systeem om het geheugen te verdelen.
In figuur 3 zie je de resultaten van dit experiment. Hoewel de memory footprint voor bijvoorbeeld ‘jemalloc’ duidelijk lager is, is er nog steeds een stijgende lijn te zien en crasht de container met een lage memory threshold. Bij het berekenen van memory fragmentatie blijkt dat we weer mis zitten: de interne fragmentatie van 1.6% en externe fragmentatie van 26.7% verklaren niet de grootte van onze RSS footprint…
En daarmee verwerpen we ook onze tweede hypothese!
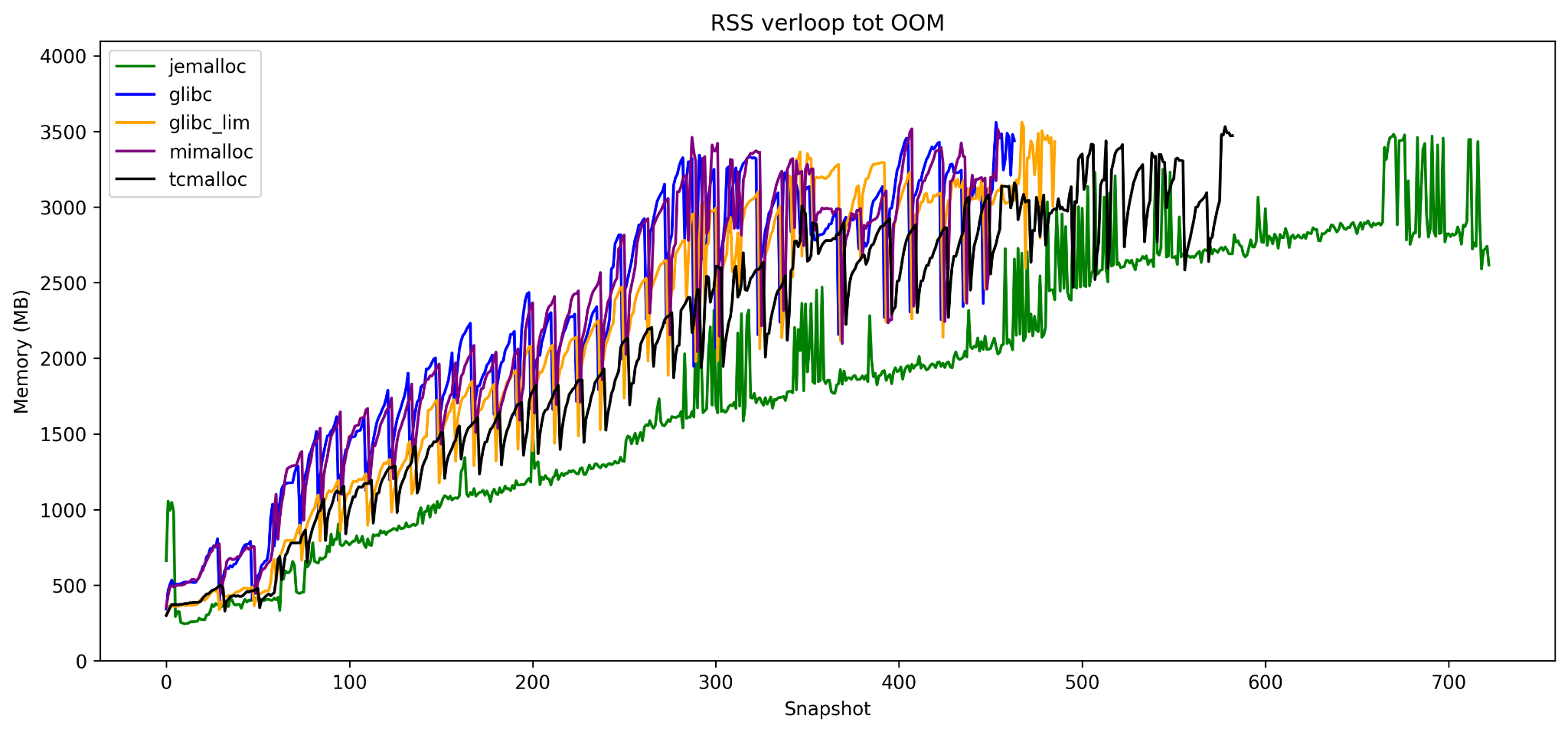
Memory verloop bij een container limiet van 4G voor een variatie aan allocators: jemalloc, glibc (de default allocator), een getunede glibc met een lagere mmap threshold, mimalloc (de default allocator van Python 3.13) en tcmalloc
Uiteindelijk blijft er nog maar 1 hypothese over: er zijn daadwerkelijk veel objecten die in memory gehouden worden, maar deze komen niet uit het Python project zelf!
We traceren het probleem naar een library die wij gebruiken, welke een hoge memory footprint heeft. Er ligt ons een moeilijke keuze voor de boeg.
Waar we bij Bessy uiteindelijk voor kiezen, dat houden we nog even voor onszelf! Ik hoop dat dit intermezzo jullie wat inzicht geeft in waar wij achter de schermen mee bezig zijn. Tot volgende maand!



